Would You Hire Me If You Knew How I Applied?
A case study in using AI, automation, and a custom-built system to navigate a job search — and the question I'm still not sure how to answer.
TL;DR: I found out in February that I am getting laid off April 1st, so instead of just refreshing my resume, I built an AI-powered job search system on top of my personal site. It scrapes and scores jobs before they hit my dashboard, runs a strengths-and-gaps analysis against my documented experience, and generates a tailored resume, cover letter, and interview prep for every role — including questions I should ask. A Chrome extension is in progress for ATS portals. I haven't auto-submitted anything yet. This article explains why, and whether any of it is actually a good idea.
An Unexpected Opportunity
In February, I found out my team was being laid off effective April 1st.
That kind of news can land two ways. You can let it be a setback, or you can treat it as a starting gun. I'm not going to pretend there wasn't a moment of pure panic and that my AirPods learned to fly — but honestly, it didn't take long to flip the lens. We're living through one of the most interesting periods in the history of technology. AI is reshaping how work gets done, how products get built, and how people find the next thing they want to work on. I had a runway, a skill set, and — maybe most importantly — some time to actually build something.
So I did.
My resume hadn't been updated since 2021. Instead of just dusting it off and sending it out, I decided to use this transition as a live proving ground. Could I apply the same tools and thinking I'd use for a client — structure, automation, AI — to my own job search? And if I did, would that make me a more competitive candidate, or raise uncomfortable questions about how hiring actually works?
That's what this is about.
First, the Honest Problem with Resumes
A resume, to me, is a weird document where you're trying to compress years of nuanced, context-dependent work into a one-page snapshot that a recruiter will read in about six seconds. And you're doing it while trying to predict which of your experiences matter most for a role you only half-understand from a job description that HR may have copy-pasted from three years ago.
The result is usually: a stale, generic document that undersells the interesting stuff and oversells the stuff you stopped caring about.
I knew I had good work to point to. I just didn't have a great way to surface it, organize it, or match it to what a specific role actually needed.
That's where this started.
Phase 1: The Brain Dump
Before I could build anything useful, I needed to get everything out of my head and into a structured place.
I set up a content layer on my personal site — decrevel.dev — backed by a PostgreSQL database, and I started moving everything there:
- Projects — things I've built, shipped, or contributed to
- Work history — roles, responsibilities, the actual story of what I did
- Highlights — standalone notable moments that don't fit neatly into a job title
- Testimonials — what other people have said about working with me
- Skills, tools, and education
The goal wasn't just storage. It was recall. When you're staring at a job description asking for something you've technically done but never formally documented, having a searchable, structured record of your own career is surprisingly powerful.
One thing that made this faster than expected: the site is connected to Claude via the Neon MCP integration. That means I can have a conversation with Claude from my phone — walking to my car, sitting at a coffee shop — and ideas, highlights, and project notes land directly in the database, tagged and structured, without me ever opening a notes app. The capture friction is basically zero.
This phase alone was clarifying. Stuff I'd dismissed as "just an agency project" turned out to be genuinely impressive when I wrote it down properly. Work I'd done with AI tools — that I'd never thought to put on a resume because it felt informal — was suddenly relevant and documentable.
Phase 2: The Job Pipeline
With my content organized, I turned my attention to the other side of the equation: the jobs themselves.
I initially set up an n8n workflow inspired by a Reddit post by SirLifeHacker to handle job scraping, but as the system matured I moved that logic directly into the site. The reason was practical: I wanted a single job import process, living in one codebase, with no risk of conflicting results. Keeping everything in one place means one source of truth. It also meant that I could more granularly break up some of my prompts (I will get to that in a future post).
The current setup uses Apify to scrape LinkedIn job postings and Vercel cron jobs to run the import on a regular schedule. But here's the part that matters: not everything that comes in hits my dashboard.
Every job gets scored on two separate questions before I ever see it:
1. Preference Score — "Would I actually want this job?" Skills overlap, remote/location fit, salary range, seniority level. This is the gatekeeper. Jobs below a threshold I control don't get saved at all.
2. Fit Score — "How competitive am I for this role?" A completely separate evaluation — core technical skills, experience level, domain relevance, secondary skills. A job can score 90 on preference and 40 on fit, or vice versa. Those are two different signals, and that separation matters.
Early versions of the system combined both into a single score. The problem: a dream job you're not qualified for would average out to something that looked "decent." Useless signal. Splitting them was one of the most clarifying design decisions I made.
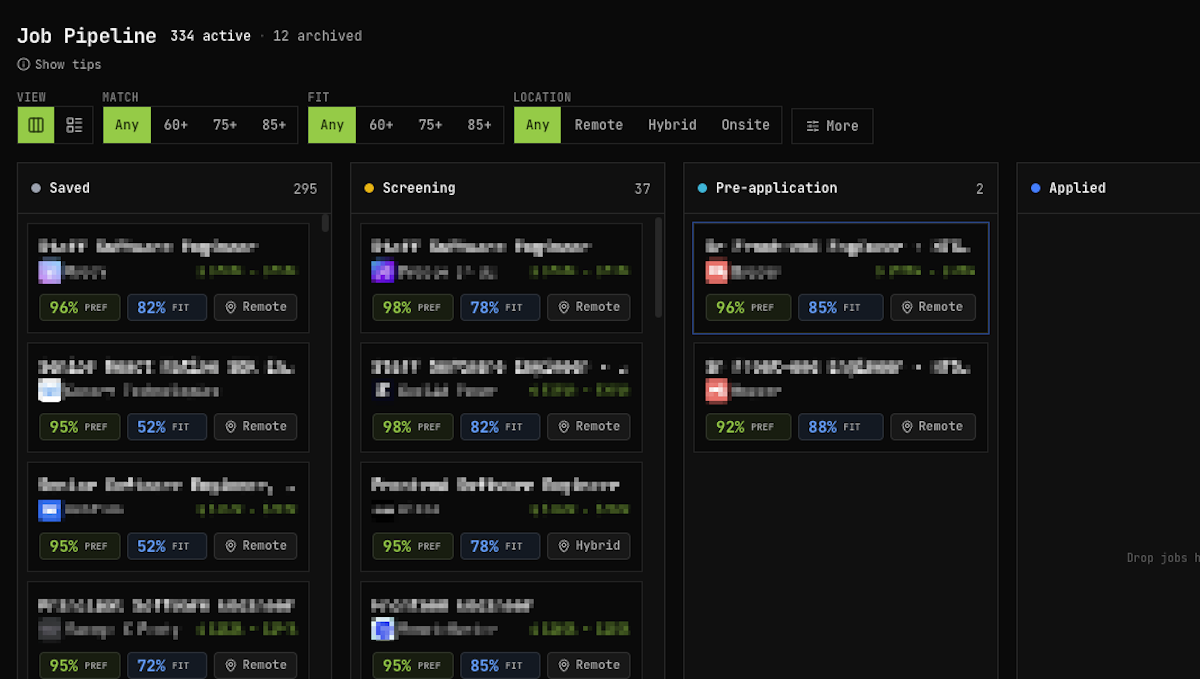
Only jobs that clear both bars make it to the dashboard, where they sit in a tracked pipeline:
- Saved — cleared the interest bar, haven't dug in yet
- Screening — actively evaluating fit
- Pre-application — preparing to apply
- Applied — submitted
This pre-filtering step is what keeps the pipeline signal-rich. I'm not wading through noise — I'm only looking at roles I'd actually consider taking and could realistically get.
Phase 3: The Fit Analysis
Once a job moves into Screening, the real evaluation kicks in — and this one is about me, not the role.
The system runs my documented experience, projects, and highlights against the specific job description and produces a strengths and gaps analysis. Here's what that looks like in practice (example output):
Role: Sr Front-end Engineer
Fit Score: 85/100
Strengths
- Expert-level React, TypeScript, Next.js, and Tailwind CSS skills with recent, production-grade experience at Under Armour and in open-source projects
- Proven track record optimizing frontend performance at scale—delivered 4x-10x improvements on high-traffic ecommerce pages, directly addressing [company name]'s performance requirements
- Deep monorepo experience (evidenced by SizeCharts.dev and The Picks Project) with modern tooling and CI/CD implementation
- Senior-level full-stack capabilities with strong product sensibility—built and launched multiple user-facing applications from conception to 12K+ users, demonstrating ability to balance shipping features with platform thinking
- Extensive ecommerce domain expertise from Under Armour and previous roles, with demonstrated understanding of complex product flows, checkout experiences, and multi-tenant platform challenges
Gaps
- No explicit travel or hospitality domain experience—while ecommerce transfers well, familiarity with travel-specific challenges (dynamic pricing, inventory systems, booking flows) would be valuable
- Limited demonstrated experience with accessibility (A11y) as a primary focus, though not uncommon in ecommerce backgrounds
- Testing expertise not prominently featured in background—no mention of test frameworks or testing strategy, which the role emphasizes as important
The gap column is where the real value is. It's not just "you're missing this skill" — it's a prompt to check whether I've actually done the work but never written it down. More often than not, I have. I just hadn't documented it.
That distinction matters. A resume gap and an experience gap are two very different problems, and the system helps me tell them apart.
Phase 4: The Skills Gap Mirror
When you're in the middle of a job search, it's easy to focus on what you have. The gap column forces you to confront what you don't — or haven't written down yet.
The system started flagging things like: "This role requires demonstrated experience with LLMs and agentic systems. No documentation found."
Which is... fair. I've been deep in AI tooling for a couple of years now — Cursor for development, ChatGPT for the longest time until I moved to Claude for almost everything, Claude Code heavily for the past year or so. I'd built real things with these tools. But I'd never formally documented any of it in a way that would survive an ATS or show up in a recruiter's search.
So the system was telling me to document it.
Then I realized: the system I was building was the documentation. The thing flagging my AI gap was itself powered by AI — processing job descriptions against my personal data, running fit analysis, generating structured output. The irony was hard to miss.
I sat with that for a minute.
Phase 5: The Dynamic Resume
With the fit score and gap analysis in hand, the next step was obvious: stop sending the same resume to every job.
Every role gets its own resume — generated dynamically from my content database, weighted toward the skills and experiences most relevant to that specific job description. The generation uses prompt engineering with a modular template system: named rule blocks assembled into variants (balanced, ats_heavy, concise) depending on the role. Same person, same real history, but presented in the way that gives me the best shot at that particular role.
After generation, the resume gets scored on two dimensions before I download it: how well it targets the job, and how well it's actually written — scan test, achievement density, executive tone, formatting consistency. If the score isn't where I want it, I know exactly what to fix.
This isn't fabrication. Nothing gets invented. It's just better prioritization — surfacing the right things instead of hoping the recruiter finds them.
Phase 6: The Cover Letter Nobody Hates Writing
Cover letters are the part of applying for jobs that I feel like everyone dreads. I understand why — writing a fresh one for every role is tedious, and the generic version ("I am excited to apply for...") probably does more harm than good.
So the same logic that drives the resume now drives the cover letter.
Once a job moves into the Pre-Application stage, the system generates a cover letter from the same content database — pulling from the fit analysis, the relevant projects, and the specific language in the job description. It's not a template with fields swapped out. It's a document built around the actual overlap between what I've done and what this role is asking for.
The cover letter gets scored too — for relevance, tone, and whether it's actually adding something the resume doesn't. If it's just restating the resume in paragraph form, that's a failure state. The goal is a document that answers the question a hiring manager hasn't asked yet: why this role, why now, why you?
I'll be honest — I was skeptical this part would be worth building. Cover letters felt like a dying format. But the output changed my mind. When the system is working from a real gap analysis and my actual documented experience, the letters read differently. Less like a sales pitch, more like a conversation.
Phase 7: Show Up Ready
Getting an interview is one thing. Walking in without having thought through the role is a different kind of failure.
This is the newest part of the system, and it might be the most practically useful one.
I feel like this has always been my worst part of the process, not because I am underprepared, I just do a horrible job remembering what I have done, and tying it back to what is asked or relevant.
So, once a job is in the Application stage, the system generates a set of likely interview questions based on the job description and my documented experience — and then answers them. Not canned answers. Answers grounded in my actual projects and highlights, matched to what the role is asking for.
So instead of getting a question like "Tell me about a time you improved site performance" in an interview and scrambling to remember something relevant — I've already worked through it. I know which project I'm referencing, what the outcome was, and how to frame it for this specific role.
But the questions go in both directions.
The system also generates a set of questions for me to ask — things that aren't already answered in the job description or the company's public materials. The goal isn't just to look engaged. It's to ask things that signal I've actually thought about the role: about the team structure, the technical roadmap, how success gets measured in the first 90 days. Questions that a candidate who did their homework would ask, because I did my homework.
This is the part of the system that's hardest to explain to people who haven't used it. It's not that the AI is preparing me — it's that having everything documented and connected means the preparation is already done. I'm not starting from scratch the night before an interview. I'm reviewing something that's been building since the job hit my pipeline.
The Part I Haven't Done Yet
Here's where I have to be honest with you: I haven't actually auto-submitted anything yet.
The system is built. The resume engine works. The cover letter generates. The interview prep is in place. The next logical step is to close the loop — automatically generate and submit a tailored application for every role that scores above a certain threshold.
I haven't pulled that trigger.
Partly because I want to review things before they go out. Partly because I'm still refining the scoring. But there's also a practical problem: not every application lives at a URL I can cleanly automate against. Some companies use Greenhouse, some use Workday, some have their own custom portals. Direct API access doesn't always exist.
So I'm also building a Chrome extension that picks up where the pipeline leaves off — for the cases where I can't automate the submission natively, the extension bridges the gap. Same resume, same cover letter, same data — but delivered wherever the application actually lives.
Partly I haven't shipped auto-submit yet because I keep coming back to the question that started this whole article:
If a hiring manager knew exactly how I applied — would they be impressed, or would they never call me back?
So Is This a Good Thing or a Bad Thing?
I've thought about this from both sides.
The case for: I'm not making anything up. Every skill, every project, every highlight in the system is real and documented. What I've built is a way to be more accurate, not less — to stop underselling the relevant stuff and stop leading with things that don't matter for a given role. The gap analysis makes me more self-aware, not less honest.
The case against: If everyone does this, does the signal disappear? If every resume is AI-optimized for every job, does the resume stop meaning anything? And when auto-submit goes live — is there even a human decision happening anymore, or just two systems talking to each other?
I don't have a clean answer. I think the honest one is: the hiring process was already broken before I built any of this. I'm just navigating the system as it exists, with the tools available to me, and maybe creating a few that give me an advantage throughout this.
What I do know is that this process — documenting my career, running honest fit analysis, identifying real gaps — has made me a better candidate. Not because the AI wrote my story, but because it helped me find it.
And honestly? That's exactly the kind of problem I want to keep solving — for myself, and eventually for others.
The Stack (For the Engineers in the Room)
If you're curious how this is actually built:
- Site: Next.js 16, TypeScript, Tailwind CSS v4
- Database: Neon PostgreSQL with Drizzle ORM
- Job scraping: Apify (LinkedIn scraper) triggered by Vercel cron jobs
- Job pipeline: Fully integrated into the site codebase — single import process, single source of truth
- AI layer: Multi-model setup using the Vercel AI SDK — Claude Haiku for fast scoring via generateObject() structured output, Claude Sonnet for resume and cover letter generation, GPT-4o-mini for lightweight extraction tasks
- Resume & cover letter generation: Modular prompt templates with named variants, scored on match quality and writing quality before download
- Interview prep: Generated from the job description + experience database — questions, drafted answers, and suggested questions to ask
- Chrome extension: In development — bridges pipeline data to job boards and ATS portals where direct automation isn't available
- MCP integration: Neon MCP connected to Claude for direct database writes from conversation — ideas, highlights, and drafts captured on the go
- Hosting: Vercel
The whole thing started as a portfolio site. It's turned into something I didn't expect — a live system that's actively shaping how I show up in a job search, and honestly, a better demonstration of what I can build than anything I could put on a resume.
What's Next
My next post will go deeper into how the scoring system actually works — the design decisions, the four iterations it took to get it right, and what's coming in V5.
If you're a developer going through something similar — or a small business owner who looked at this and thought "I need something like this for my own content and presence" — I'd genuinely love to talk. This kind of system isn't just for job searches. The underlying idea — organizing your expertise, matching it to what people actually need, presenting it in context — applies almost everywhere.
Grab some time on my calendar or reach out directly. I don't ghost people.