decrevel.dev — Personal Site & AI-Powered Job Search Platform
A full-stack Next.js 16 application serving three subdomains, backed by 40+ Neon PostgreSQL tables, 20+ external service integrations, and an autonomous AI-driven job search pipeline built on Claude and OpenAI.
What It Is
Most portfolio sites are brochures. This one is a working system.
decrevel.dev started as a place to put my work. It's grown into something I actually rely on — a site that tracks my job search, generates tailored resumes, logs every workout and song I've listened to, lets people book time with me, and runs a background AI pipeline that finds job matches while I sleep.
It's built on Next.js, connected to over 20 external services, and backed by a Postgres database with 40+ tables. But the tech is less interesting than what it does.
The AI Pipeline
Every 12 hours, the site scrapes LinkedIn for relevant job listings, scores each one against my background, and sends me a Slack notification for anything worth looking at. I don't log in to check. I don't scroll listings. The system decides what reaches me — and most jobs don't make it.
Scoring happens in two passes. The first evaluates whether I'd actually want the job: skills overlap, location, salary range, seniority level. Below a threshold I control, the job is discarded. Above it, a second pass runs — this one focused on how competitive I am for the role, weighted across core technical skills, experience level, domain relevance, and secondary skills. Both scores, the reasoning, and a full strengths-and-gaps breakdown get stored on the job record.
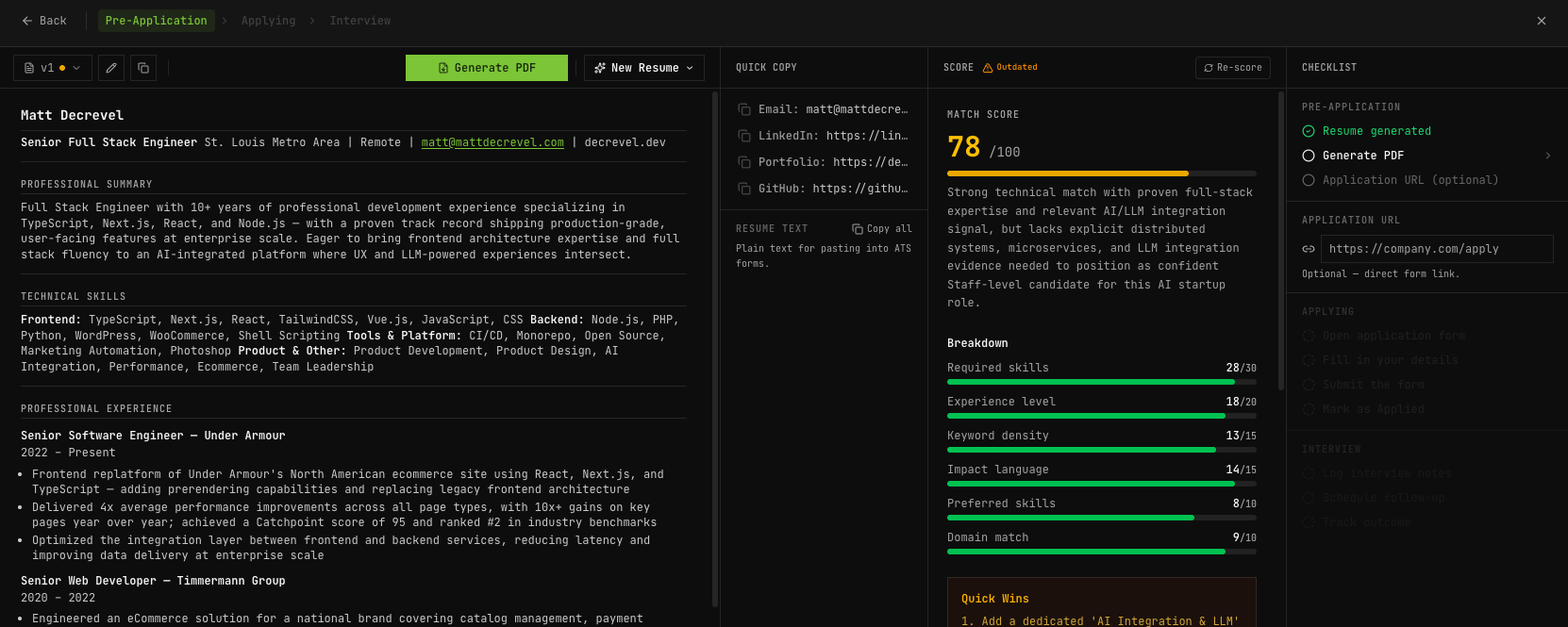
Both passes run through the Anthropic API via the Vercel AI SDK's generateObject() with Zod schema validation — the model returns typed, validated JSON on every call. Claude Haiku handles scoring (fast, cheap, runs on every scraped job). Claude Sonnet handles resume generation — only when I've decided a role is worth pursuing.
Resume generation uses a modular prompt engineering system: named rule blocks assembled into variants (balanced, ats_heavy, concise) depending on the job type. Static sections like education and contact pass through verbatim from the database. The AI handles summary framing, skills ordering, bullet selection, and project inclusion — always from real documented experience. After generation, a 6-category match rubric and a separate writing quality scorer evaluate the output before I download anything.
Beyond the job pipeline, the site uses LLM integration in four additional places: structured extraction via GPT-4o-mini for lightweight parsing tasks, a streaming chat interface via streamText(), AI-powered idea capture through the Neon MCP integration, and per-call usage tracking (model, tokens, estimated cost) logged to Postgres on every request.
Connected to Claude Directly
One of the more practical things I've built into this system is a direct connection between Claude and the site's database via the Neon MCP (Model Context Protocol) integration.
In practice, this means I can have a conversation with Claude — from my phone, on the go, whenever an idea comes up — and it writes directly to the site's database. New post ideas, project notes, content drafts, highlights worth capturing: instead of dropping them into a notes app I'll never revisit, they land in the right table, tagged and ready to work with. The site is also built and maintained through this same workflow — Claude reads the schema, understands the content model, and operates the system as a collaborator, not just a tool.
The Database
The database is Postgres, hosted on Neon, with Drizzle ORM as the query layer. Drizzle was the right choice here — it's TypeScript-native, the schema lives in code alongside everything else, and it generates clean SQL migrations rather than hiding what's actually happening at the database level.
The schema has grown to 40+ tables covering content, job search, a personal book library, a consulting CRM, OAuth token storage, analytics, and more. Relationships are handled through junction tables with composite primary keys. For anything PostgreSQL-specific that Drizzle's query builder doesn't express cleanly — distinct counts, date formatting, null handling in sort order — raw SQL template literals fill the gap:
The analytics system runs nine queries in parallel via Promise.all() on every dashboard load — totals, daily breakdown, top pages, referrers, geographic distribution, device and browser split, and session depth for bounce rate. Migrations are managed through Drizzle Kit with separate connection strings for runtime (pooled via PgBouncer) and migrations (direct).
The Data Dashboards
labs.decrevel.dev is a personal data playground.
- Music — connected to Spotify, it tracks what I'm listening to, builds a profile of my taste over time, and shows what's playing right now across the main site
- Move — connected to Strava, it aggregates every run and ride into a full dashboard: personal records, pace trends, monthly comparisons, streaks
- Watching — connected to Trakt, it keeps a running log of every movie and TV episode I've watched, with ratings and a watchlist
- Reading — a personal book library tracking what I'm currently reading, what I've finished, and what's on deck, with ratings and a custom database behind it
None of this is groundbreaking individually. Together it's a single place where I can actually see patterns in how I spend my time.
Built to Be Useful, Not Just Impressive
Custom analytics. Instead of dropping a third-party tracking script on the page, visitor data lives in the same database as everything else. That means I can query it the same way I query any other content — no dashboard login, no vendor lock-in.
Booking built in. There's a scheduling flow connected to Cal.com throughout the site. Anyone can book time without leaving the page or dealing with a separate tool.
Everything updates itself. Content is cached at the CDN edge and refreshes automatically when something is published. The job scraper runs on a schedule. Token refresh for connected services happens in the background. The goal was a system that requires as little maintenance as possible while staying current.
The Stack
Next.js 16, TypeScript, Tailwind CSS, Postgres on Neon, Drizzle ORM, deployed on Vercel. AI via Anthropic (Claude API) and OpenAI. Integrations include Spotify, Strava, Trakt, Apify, Cloudinary, Cal.com, Resend, Dub.co, and Slack. Testing with Vitest. Prompt engineering, structured LLM output, streaming responses, and autonomous agentic workflows built with the Vercel AI SDK.